Please note that the following content is intended for personal note-taking, and therefore is rather unorganized. On the occasion of any issues, please email me or make a thread in the comment section below.
Position-Wise FFN
F2(ReLU(F1(XA))),
for every time step, apply the same MLP to improve network expression ability (promote then reduce dimensionality). It’s a trick to control the scale issue.
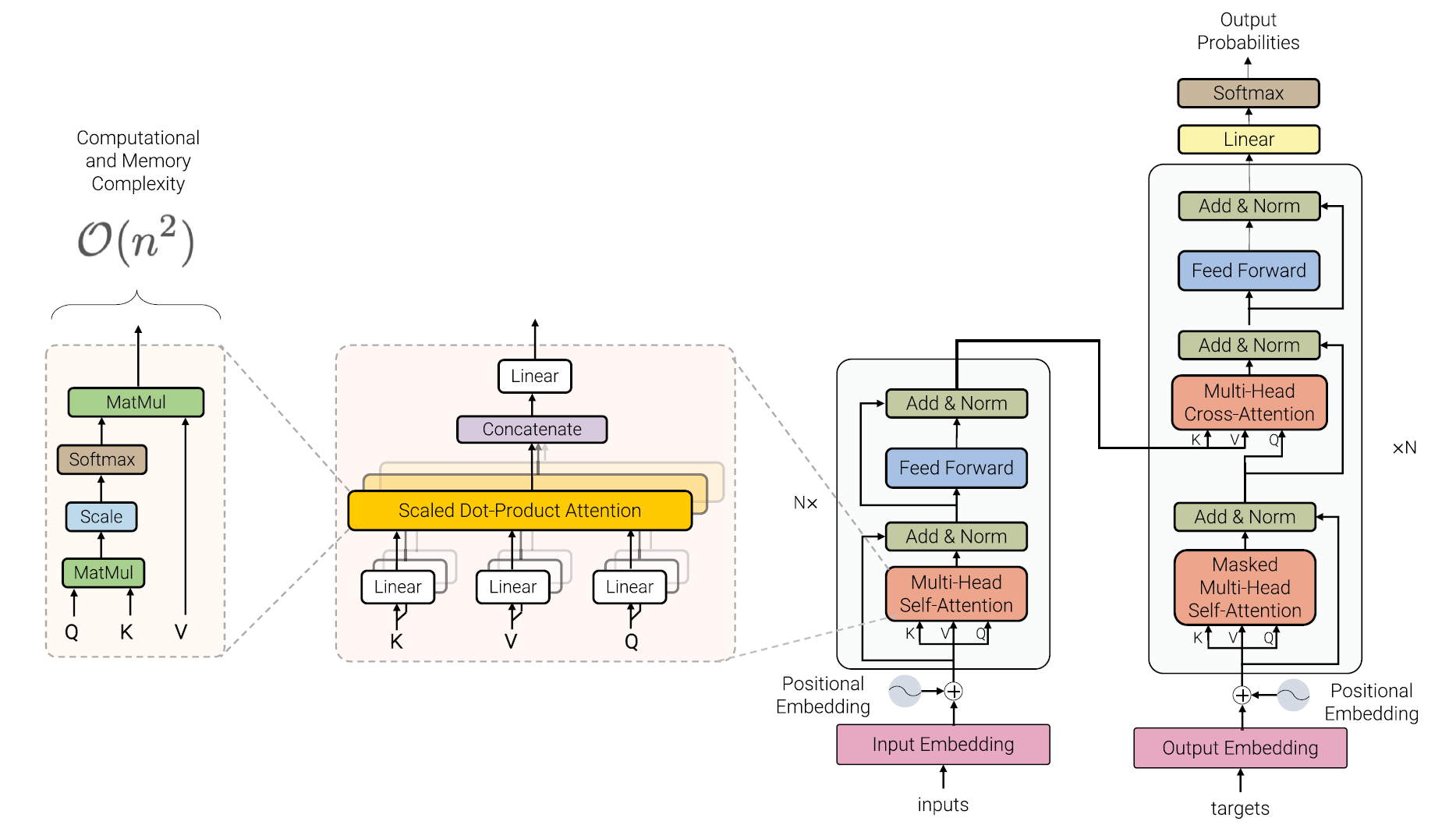
Computation Cost
memory & cc: quadratic. N×N
Mode
(1) encoder-only (e.g. for classification),
(2) decoder-only(e.g. for language modeling), causal, upper triangular mask
(3) encoder-decoder (e.g. for machine translation), decoder part causal due to auto-regressive.
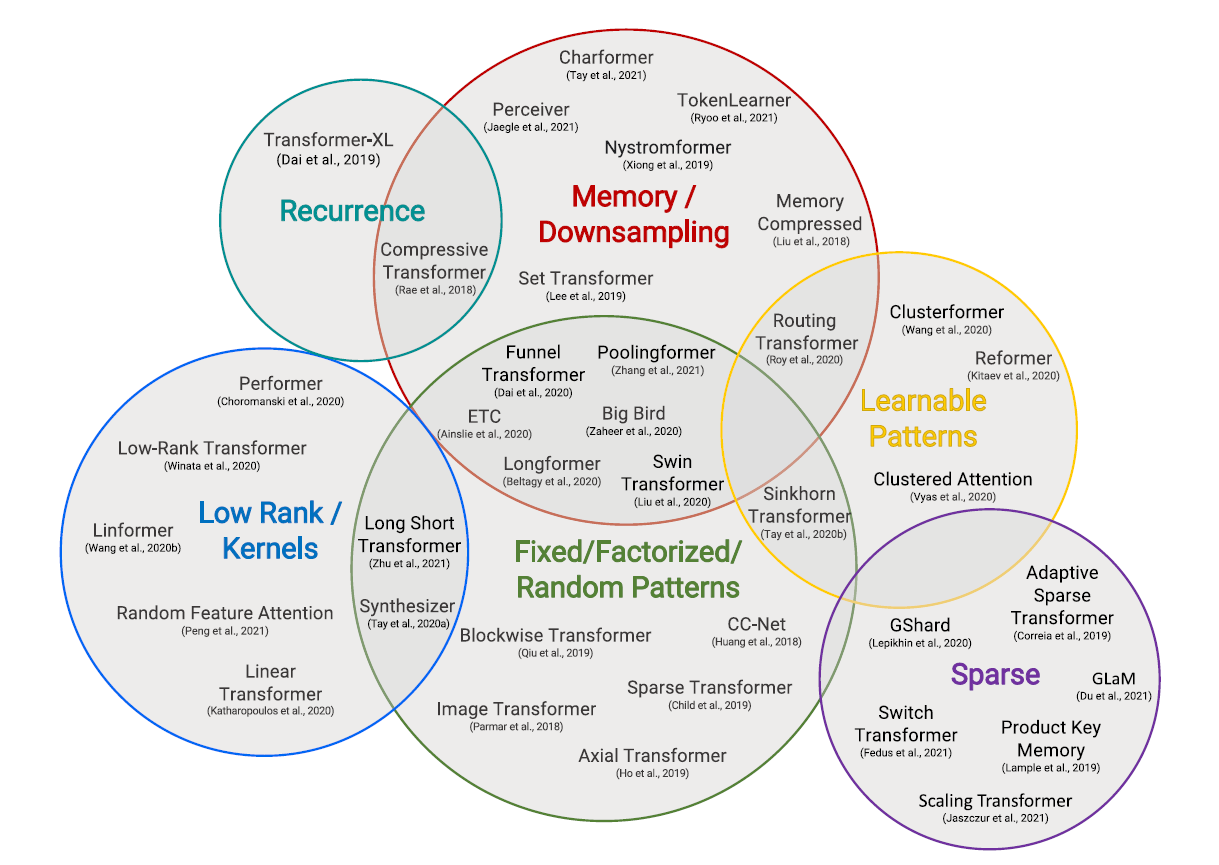
Modifications
Methodology
FP (fixed patterns): local windows etc.
Block-wise Patterns: N2→B2
Strided Patterns: tending by intervals. Strided or dilated windows.
Self-attention computed within blocks independently.
for block of length b, cc=O(b2∗(n/b))=O(n)
Memory-Compressed Attention
For Kd×N, apply convolution along axis 0 with kernel size and stride k to reduce dimension to d×kN. CC of attention then becomes O(n⋅n/k).
However, it often either
does not result in significant improvement in cc due to N and N/k being similar in orders of magnitude; or
lose information during compression.
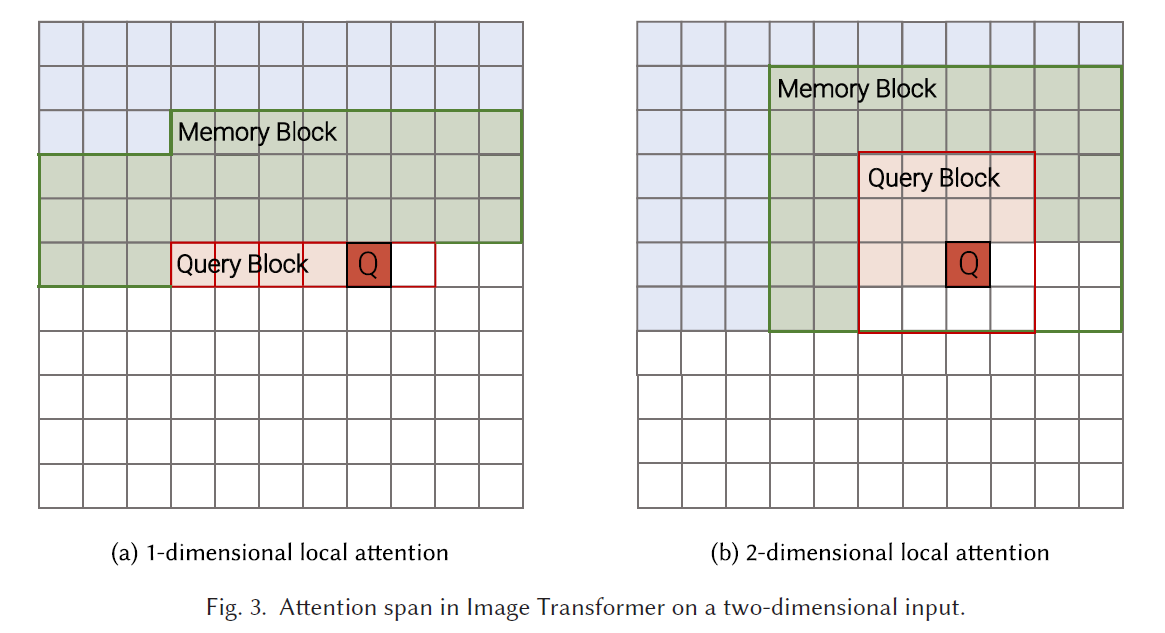
Two Attention Schemes
flattened in raster order, partition into non-overlapping query blocks of length lq, extends lmto memory blocks. m=lq+lm,cc=O(n⋅m).
Loses global receptive field.
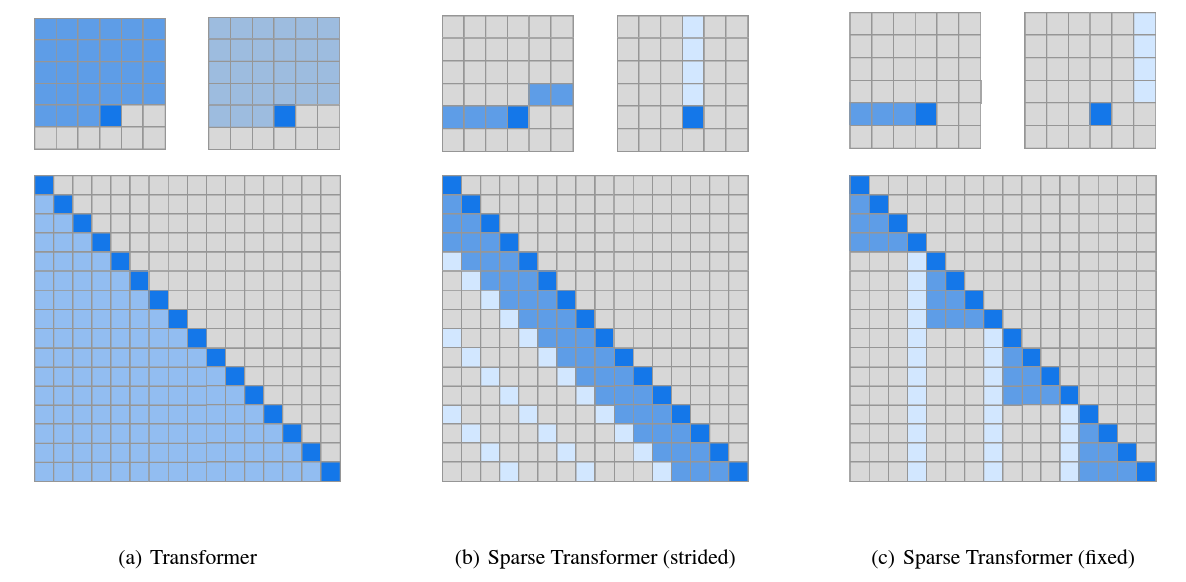
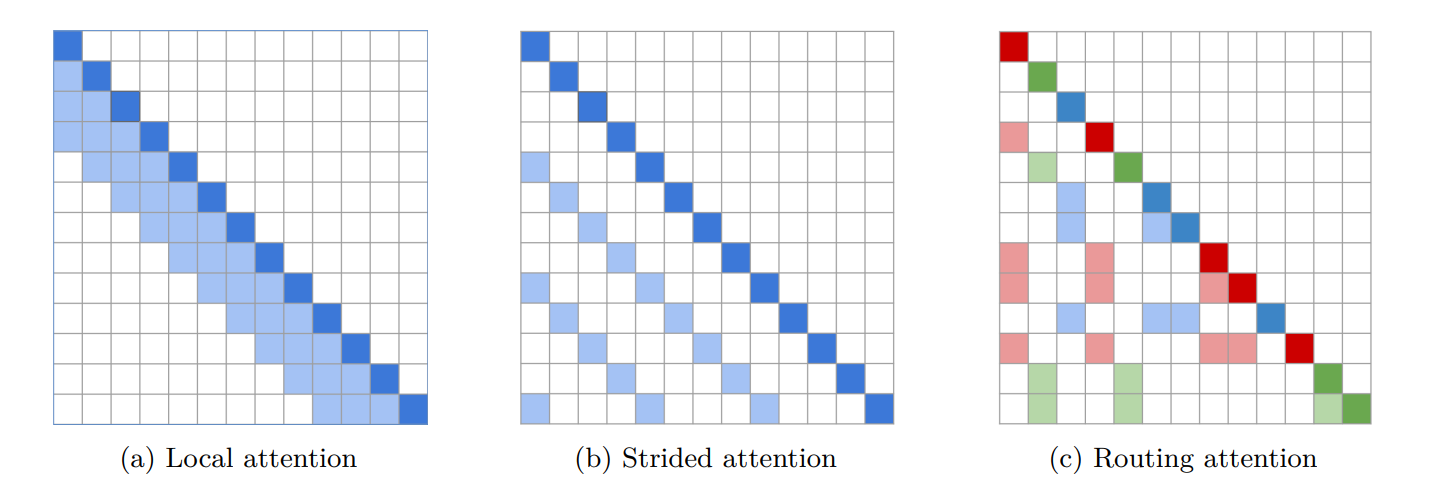
Sparse Transformer
Assumption: In softmax Attention, effective weights are sparsely distributed.
heads
1/2 fixed:
FA^ij(1)={QiKj⊤,0 if ⌊j/L⌋=⌊i/L⌋ otherwise FA^ij(2)={QiKj⊤,0 if jmodL≥L−c otherwise +1/2 strided:
SA^ij(1)={QiKj⊤,0 if max(0,i−L)≤j≤i otherwise SA^ij(2)={QiKj⊤,0 if (i−j)modL=0 otherwise
which can be visualized below:
usage
alternate 1 and 2: attention(X)=Wp⋅attend(X,A(rmodp))
Justification: 1 synthesizes block information, so striding in 2 does not affect the receptive field.
merge: attention(X)=Wp⋅attend(X,⋃m=1pA(m))
multihead, then concatenate: attention(X)=Wp(attend(X,A)(i))i∈{1,…,nh}
cc
set L=N, then O(NN).
Strided attention is more suited for images and audio; (more local)
fixed attention is more suited for texts. (more global)
Blockwise Self-Attention
Memory: for BERT, model 2.1%, optimizer(adam)10.3%, activation 87.6%O(N2).
BlockBERT: split N→n×nN, then Q→Q1,Q2,...Qn, same for K,V.O(n2N2×n)=O(nN2)
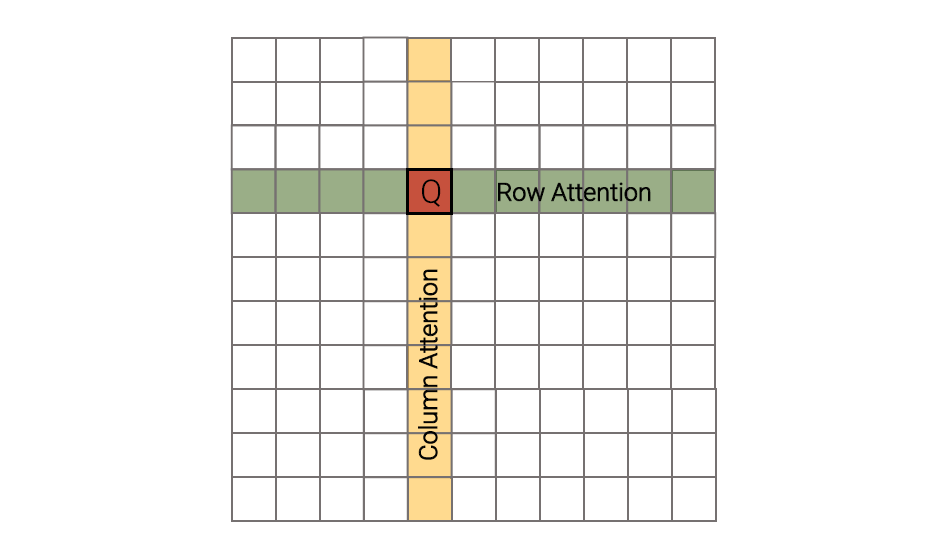
Axial Transformer
Compute attention along axis. For image data, B×N×hw→Bw×N×h+Bh×N×w
saves O(N2)/O(NN)=O(N)
Generally, for N=N1/d×⋯×N1/d, Axial transformer saves O(N2)/O(d×(N1/d)(d−1)×(N1/d)2)=O(N(d−1)/d)
models
auto-regressive: pθ(x)=∏i=1Npθ(xi∣x<i)Inner decode: row-wise modelh←Embed(x)h← ShiftRight (h)+ PositionEmbeddings h← MaskedTransformerBlock 2(h)×Lrow
where h is the initial D dimensional embedding of size H×W×D.
shiftright ensures the current pixel is out of receptive field.
Outer Decoder: capturing the rows aboveh←Embed(x)u←h+ PositionEmbeddings u← MaskedTransformerBlock 1(TransformerBlock2(u))×Lupper /2h←ShiftDown(u)+ShiftRight(h)+ PositionEmbeddings h← MaskedTransformerBlock 2(h)×Lrow
The tensor u represents context captured above the current pixel.
Finally, pass through LayerNorm and dense layer to produce logits H×W×256.
Effective for point clouds, etc.
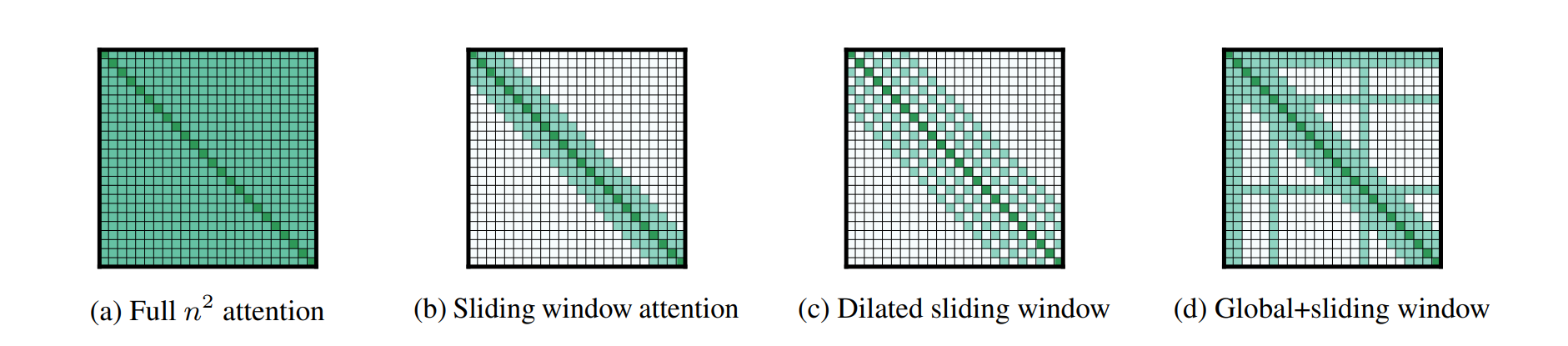
Longformer
dilated CNNs → dilated sliding windows Qs,Ks,Vs
Increases the receptive field by layer like CNN, and therefore this indirect approach performs similarly bad at long distance modeling.
special tokens for global attention (BERT [CLS]) Qg,Kg,Vg , which needs to attend to and be attended by all tokens. Crucial.
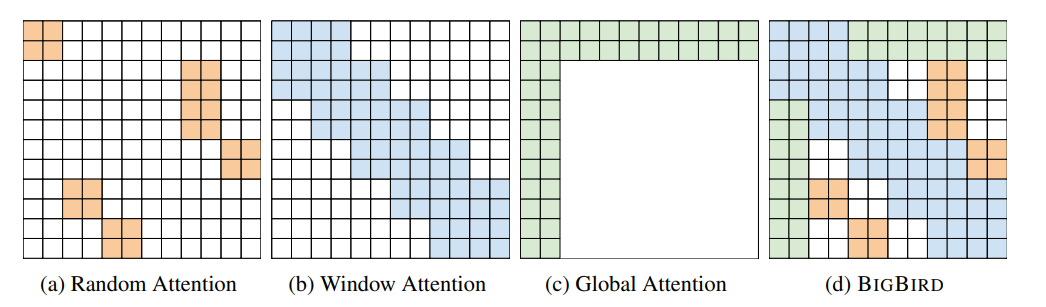
Big Bird
global tokens + fixed patterns (local sliding windows)+ random attention (queries attend to random keys).
Justification for randomness:
The standard Transformer is a complete digraph, which can be approximated with random graphs.
The model is Turing-complete.
Routing Transformer
learns attention sparsity with k-means clustering where k=n.
Cluster centroid vectors μ=(μ1,⋯,μk)∈Rk×d are shared for Q and K.Xi′=∑j:Kj∈μ(Qi),j<iAijVj
For decoder (causal attention), solutions include:
additional lower-triangular masking;
share queries and keys. Namely, k←Q. Works better.
Reformer
Locality Sensitive Hashing (LSH).
For b hashes, define random matrix Rdk×2b.h(x)=argmax([xR;−xR])
similarity with b random vectors.
attention: oi=∑j∈Piexp(qi⋅kj−z(i,Pi))vj where Pi={j:h(qi)=h(kj)}where z is the normalizing term in softmax.
To avoid queries with no keys, set kj=∥qj∥qj s.t. h(kj)=h(qj).
Multi-round: Pi=⋃r=1nround Pi(r).
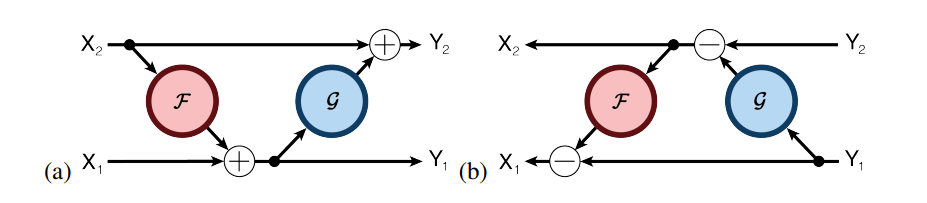
Revnet:
Reduce memory (activation) cost with extra computation.
In reformer, set F to LSH attention blocks, and g to FFN.
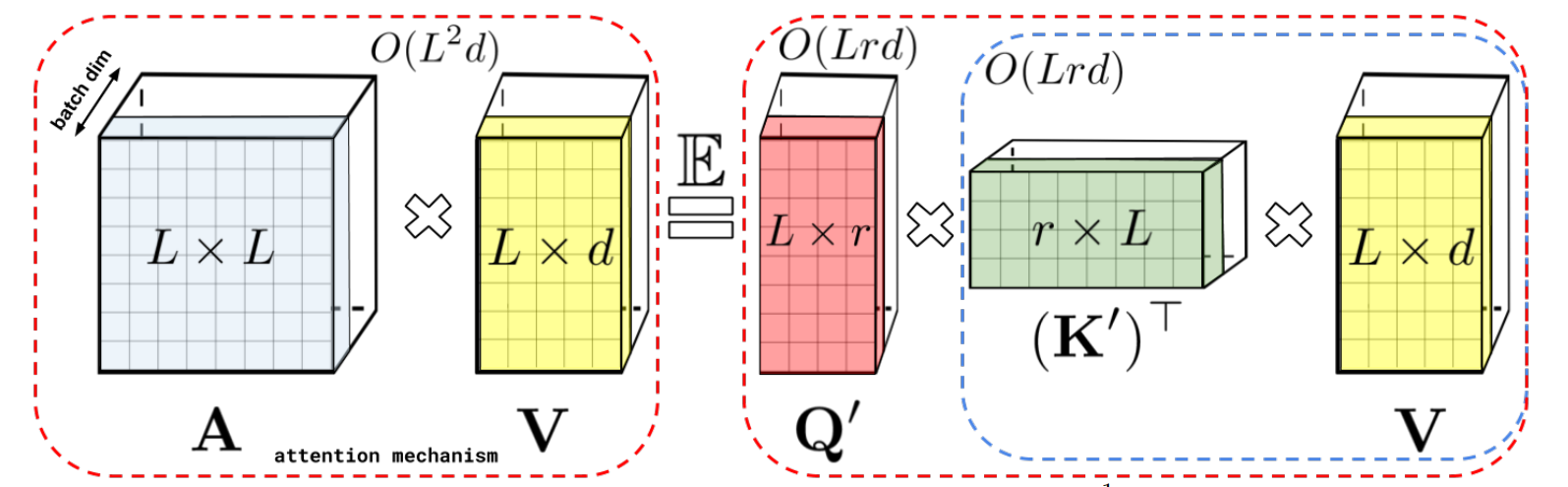
Linformer
N×d→k×d, reduction on N dimension instead of k. Needs to maintain causal masking.
Softmax(dk1XWiQ(EiXWiK))⋅FiXWiV
where Ei,Fi are k×N projections.
Reminiscent of depth-wise convolutions/ pooling.
Performer
Fast Attention via Orthogonal Random Features (FAVOR):
With Kernel K(x,y)=E[ϕ(x)⊤ϕ(y)], where ϕ is a random feature map, we can write attention as A(i,j)=K(qi⊤,kj⊤), then
Att↔(Q,K,V)=D−1(Q′((K′)⊤V)),D=diag(Q′((K′)⊤1L))
slower on causal(autoregressive) due to additional steps for masking, therefore unable to be parallelized.
Linear Transformer
kernel method, linear-time, constant memory RNN.
sim(q,k)=exp(dqTk), observe:
Vi′=∑j=1psim(Qi,Kj)∑j=1psim(Qi,Kj)Vj.
with kernel method: sim(q,k):=ϕ(q)Tϕ(k), then
Vi′SpZp=ϕ(Qi)TZpϕ(Qi)TSp,:=j=1∑pϕ(Kj)VjT,:=j=1∑pϕ(Kj).
for unmasked, Qi attends to the same N keys, therefore we simply reuse Sp,Zp.
for masked, incremental:
Si=Si−1+ϕ(Ki)ViT,Zi=Zi−1+ϕ(Ki)
if O(c) to compute ϕ, then cc is O(Ncd).
choose: ϕ(x)=elu(x)+1, then c=d.
References
[1] Yi Tay, Mostafa Dehghani, Dara Bahri, and Donald Metzler. 2022. Efficient Transformers: A Survey. ACM Comput. Surv. 55, 6, Article 109 (December 2022), 28 pages. https://doi.org/10.1145/3530811
 For decoder (causal attention), solutions include:
For decoder (causal attention), solutions include: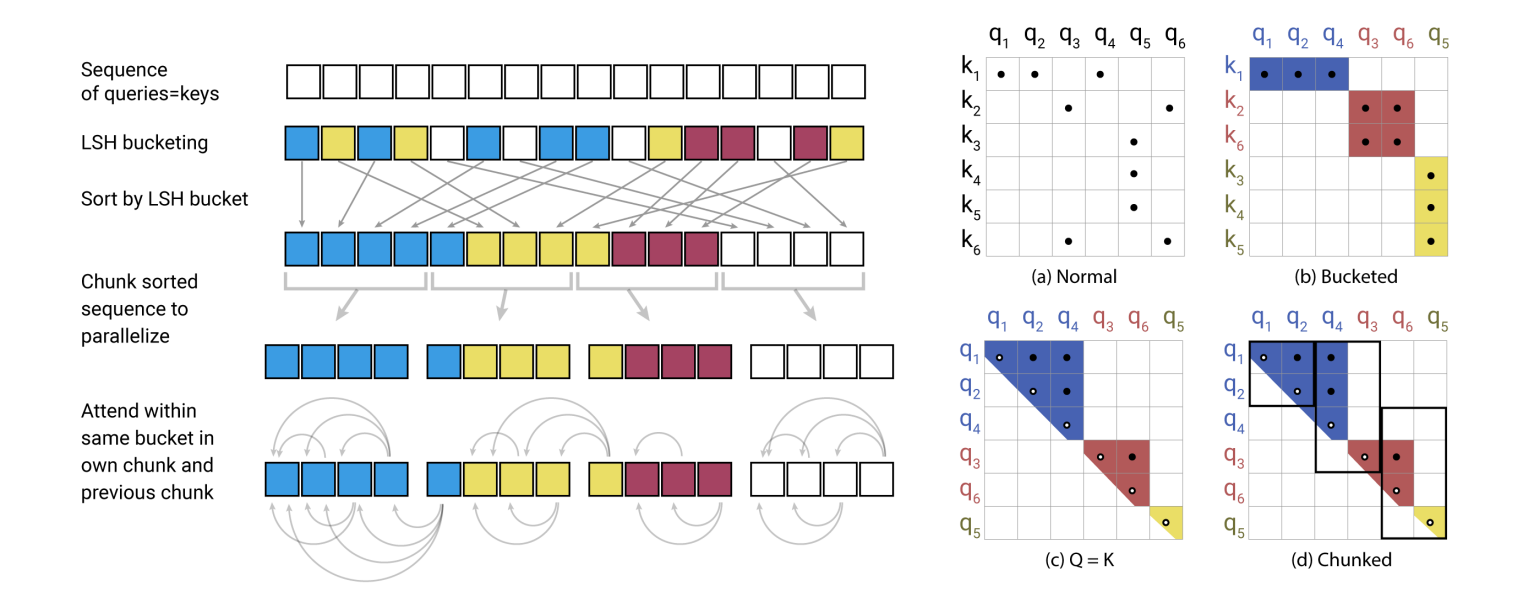 To avoid queries with no keys, set s.t.
Multi-round:
To avoid queries with no keys, set s.t.
Multi-round: