Readers are recommended to have prior knowledge for Reinforcement Learning basics. A good tutorial can be found here.
Introduction
Policy Optimization and Q-Learning are two main model-free RL approaches. While the former is more principled and stable, the latter exploits sampled trajectories more efficiently. Soft Actor-Critic, or SAC, is an interpolation of both approaches.
Policy Gradient
Following stochastic parameterized policy πθ, we can sample trajectory τ. The aim is to maximize the expected return J(πθ)=τ∼πθE[R(τ)]. We aim to update θ via gradient descent θk+1=θk+α∇θJ(πθ)∣θk.
The gradient ∇θJ(πθ) can be expanded into:
∇θJ(πθ)=∇θτ∼πθE[R(τ)]=∇θ∫τP(τ∣θ)R(τ)=∫τ∇θP(τ∣θ)R(τ)=∫τP(τ∣θ)∇θlogP(τ∣θ)R(τ)=τ∼πθE[∇θlogP(τ∣θ)R(τ)]=τ∼πθE[t=0∑T∇θlogπθ(at∣st)R(τ)].
Entropy-Regularized Reinforcement Learning
Q-function tends to dramatically overestimate Q-values, which then leads to the policy breaking because it exploits the errors in the Q-function. To address this issue, we ought to discount the Q-values by some metric.
The entropy H of a random variable x∼P is defined as:
H(P)=x∼PE[−logP(x)]
At each time step t, we give the agent a bonus reward proportional to the entropy of the policy. The Bellman Equation is thus changed to:
Qπ(s,a)=s′∼Pa′∼πE[R(s,a,s′)+γ(Qπ(s′,a′)+αH(π(⋅∣s′)))]=s′∼Pa′∼πE[R(s,a,s′)+γ(Qπ(s′,a′)−αlogπ(a′∣s′))]
where α is the trade-off coefficient (or temperature). Higher temperature encourages early exploration and prevents the policy from prematurely converging to a bad local optimum.
We can approximate the expectation with samples from the action space:
Qπ(s,a)≈r+γ(Qπ(s′,a~′)−αlogπ(a~′∣s′)),a~′∼π(⋅∣s′)
Q-Learning Side
Mean Squared Bellman Error
The Bellman equation describing the optimal action-value function is given by:
Q∗(s,a)=s′∼PE[r(s,a)+γa′maxQ∗(s′,a′)]
With sampled trajectories (s,a,r,s′,d) stored in replay buffer D, we learn an approximator to Q∗(s,a) with neural network Qϕ(s,a).
The mean squared Bellman Error (MSBE) is computed as:
L(ϕ,D)=(s,a,r,s′,d)∼DE[(Qϕ(s,a)−(r+γ(1−d)a′maxQϕ(s′,a′)))2]
where d=1 if s′ is a terminal state and 0 otherwise.
Target Networks
The optimization target is given by:
y(r,s′,d)=r+γ(1−d)a′maxQϕ(s′,a′)
Since we wish to get rid of the parameters ϕ in the target to stabilize the training process, we replace it with the target network ϕtarg which is cached and only updated once per main network update by Polyak averaging:
ϕtarg←ρϕtarg+(1−ρ)ϕ.
Clipped double-Q
To further suppress Q-values, in SAC we learn two Q-functions instead of one, regressing both sets of parameter ϕ with a shared target, calculated with the smaller Q-value of the two:
y(r,s′,d)=r+γ(1−d)i=1,2min(a′maxQϕi,targ(s′,a′)),L(ϕi,D)=E(s,a,r,s′,d)∼D[(Qϕi(s,a)−y(r,s′,d))2].
Policy Learning Side
Since calculating maxaQϕ(s,a) is expensive, we can approximate it with maxaQ(s,a)≈Qϕ(s,μθtarg(s)), where μθtarg is the target policy. The objective then becomes to learning a policy that maximizes Qϕ(s,a):maxθs∼DE[Qϕ(s,μθ(s))].
Here we adopt a squashed state-dependent gaussian policy:
a~θ(s,ξ)=tanh(μθ(s)+σθ(s)⊙ξ),ξ∼N(0,I).
Under the context of Entropy-Regularized Reinforcement Learning, we modify the target with:
y(r,s′,d)=r+γ(1−d)(j=1,2minQϕtar,j(s′,a~′)−αlogπθ(a~′∣s′)),a~′∼πθ(⋅∣s′)
This reparameterization removes the dependence of the expectation on policy parameters:
a∼πθE[Qπθ(s,a)−αlogπθ(a∣s)]=ξ∼NE[Qπθ(s,a~θ(s,ξ))−αlogπθ(a~θ(s,ξ)∣s)]
We perform a gradient ascent optimizing:
θmaxs∼Dξ∼NE[j=1,2minQϕj(s,a~θ(s,ξ))−αlogπθ(a~θ(s,ξ)∣s)],
CQL-SAC
Since we are trying to do offline-online combined updates for performance improvement, we need to tackle with the offline reinforcement learning problem with generated samples. From prior works regarding offline RL [6][7], OOD actions and function approximation errors will pose problems for Q function estimation. Therefore, we adopt conservative Q-learning method proposed by prior work [8] to address this issue.
Conservative Off-Policy Evaluation
We aim to estimate the value Vπ(s) of a target policy π given access to a dataset Dβ generated by pretrained SAC behavioral policy πβ(a∣s). Because we are interested in preventing overestimation of the policy value, we learn a conservative, lower-bound Q-function by additionally minimizing Q-values alongside a standard Bellman error objective. Our choice of penalty is to minimize the expected Q-value under a particular distribution of state-action pairs μ(s,a). We can define a iterative optimization for training the Q-function:
Q^k+1←argminQαEs∼Dβ,a∼μ(a∣s)[Q(s,a)]+21Es,a∼Dβ[(Q(s,a)−B^πQ^k(s,a))2]
where B^π is the Bellman operator and α is the tradeoff factor. The optimality for this update as: Q^π=limk→∞Q^k and we can show it lower-bounds Qπ for all state-action pairs (s,a). We can further tighten this bound if we are only interested in estimating Vπ(s). In this case, we can improve our iterative process as:
Q^k+1←argminQα(Es∼Dβ,a∼μ(a∣s)[Q(s,a)]−Es∼Dβ,a∼πβ(a∣s)[Q(s,a)])+21Es,a∼Dβ[(Q(s,a)−B^πQ^k(s,a))2]
By adding a Q-maximizing term, although it may not be true for Q^π being the point-wise lower-bound for Qπ, we still have Eπ(a∣s)[Q^π(s,a)]≤Vπ(s) when μ(a∣s)=π(a∣s). For detailed theoretical analysis, we will refer to prior work [8].
Conservative Q-Learning for Offline RL
We now adopt a general approach for offline policy learning, which we refer to as conservative Q-learning (CQL). This algorithm was first presented by prior work [8]. We denote CQL(R) as a CQL algorithm with a particular choice of regularizer R(μ). We can formulate the optimization problem in a min-max fashion:
minQmaxμα(Es∼Dβ,a∼μ(a∣s)[Q(s,a)]−Es∼Dβ,a∼πβ(a∣s)[Q(s,a)])+21Es,a,s′∼Dβ[(Q(s,a)−B^πkQ^k(s,a))2]+R(μ)
Since we are utilizing CQL-SAC, we will chose the regularizer as the entropy H, making it CQL(H). In this case, the optimization problem will be reduced as:
minQαEs∼Dβ(loga∑exp(Q(s,a))−Es∼Dβ,a∼πβ(a∣s)[Q(s,a)])+21Es,a,s′∼Dβ[(Q(s,a)−B^πkQ^k(s,a))2]
More specifically, we let the regularizer R(μ)=−DKL(μ,ρ), where ρ(a∣s) is a prior distribution. We can then derive μ(a∣s)∝ρ(a∣s)exp(Q(s,a)). We take the prior distribution as a uniform distribution ρ=Unif(a). In this way, we can retrieve the optimization target above. For detailed derivations and theoretical analysis we refer to [8].
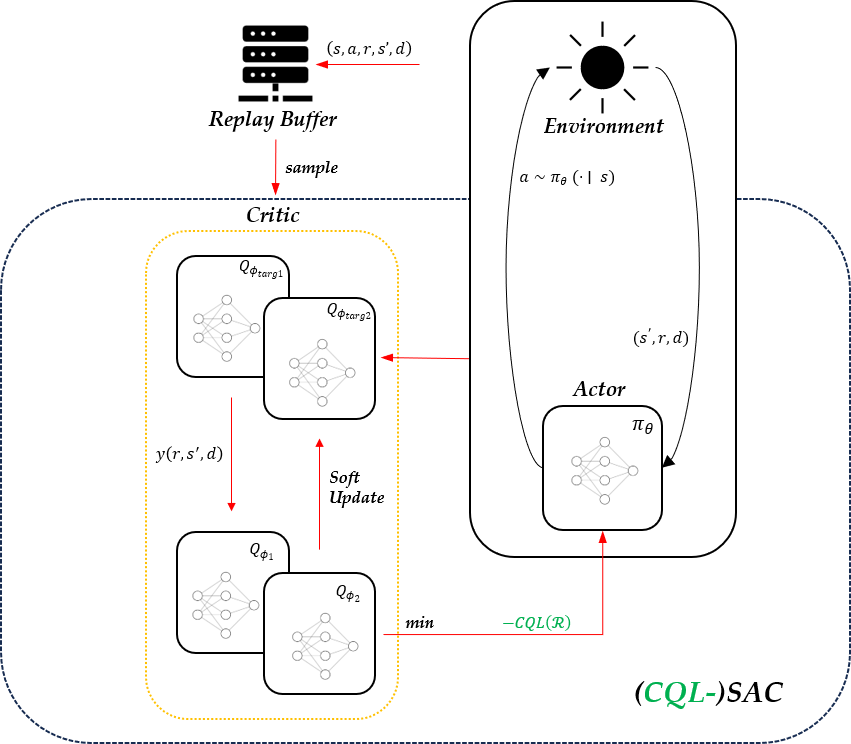
Architecture
Architecture for SAC and its CQL-modified version is illustrated as follows:
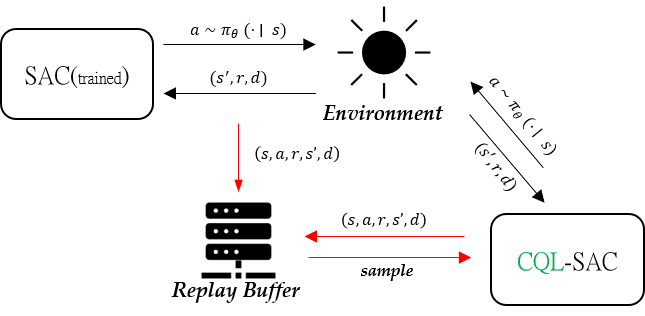
The overall pipeline is visualized below:
Pseudocode

Implementation
For an implementation of the CQL-SAC algorithm, please refer to our Github repo.
PDF
Online-offline combined training for CQL-SAC
Expand to read the PDF.
References
[1] Spinning Up in Deep Reinforcement Learning, Achiam, Joshua, (2018).
[2] Haarnoja, Tuomas, et al. “Soft actor-critic algorithms and applications.” arXiv preprint arXiv:1812.05905 (2018).
[3] Kumar, Aviral, et al. “Conservative q-learning for offline reinforcement learning.” Advances in Neural Information Processing Systems 33 (2020): 1179-1191.
[4] Zhang, Shangtong, and Richard S. Sutton. “A deeper look at experience replay.” arXiv preprint arXiv:1712.01275 (2017).
[5] Fujimoto, Scott, Herke Hoof, and David Meger. “Addressing function approximation error in actor-critic methods.” International conference on machine learning. PMLR, 2018.
[6] Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems. arXiv preprint arXiv:2005.01643, 2020.
[7] Aviral Kumar, Justin Fu, Matthew Soh, George Tucker, and Sergey Levine. Stabilizing off-policy q-learning via bootstrapping error reduction. In Advances in Neural Information Processing Systems, pages 11761–11771, 2019.
[8]Aviral Kumar, Aurick Zhou, George Tucker and Sergey Levine. Conservative q-learning for offline reinforcement learning. In Advances in Neural Information Processing Systems, 2020.